 FORDHAM FORENSICS When It Really Matters770-777-2090
FORDHAM FORENSICS When It Really Matters770-777-2090

Contents
Introduction
Why Litigation Fails
How System Engineering Works
How Plans Appear in the Rules
Eleven Steps for Designing a Plan
1. Scope of Discovery and Order
2. Preserve the Data
3. Schedule of Discovery
4. Validate The Population
- Compound Documents Parsed
- Calculate Hashes
- Perform Signature Analysis
- Known Files Identified
- Encryption Detection
- Deleted File Recovery
- File System Data Collected
- Search Indexes Constructed
- File Activity Collected
7. Handling of Privilege and Restricted Documents
8. Process and Produce Documents
9. Disputes Resolution
10. Assign Cost Responsibility
Inquiries
To learn more about electronic discovery or
discuss a specific matter,
770-777-2090
E-Mail
Eleven Steps to Designing an E-Discovery Plan and Protocol:
A Systems Engineering Approach to Modern Litigation
Gregory L Fordham
(Last updated December 2015)
Successful managers of complex projects know the importance of good planning. In fact, successful managers of all kinds of complex endeavors like software products, hardware items, building construction, military operations and even professional services know the importance of good planning in delivering a final product that performs as intended as well as one that satisfies its cost and schedule criteria.
Litigation is a complex product, too. It has many parts like pleadings, orders, reports, hearings and the trial itself. One of the largest components to any litigation is discovery, which itself has many elements that must be optimized for efficiency and effectiveness, including a document management system that is often the central resourcce for capturing, organizing and marshalling the facts of every litigation.
If one were building a house, the end result could be described on the back of a napkin. Everyone knows, however, that such an approach is a prescription for disaster. As a result, it is widely accepted that a well conceived and detailed drawing package is the best approach for building a house because it will resolve many issues on the front end and thereby avoid many disputes on the back-end as well as reduce waste as a result of ordering mistakes or even assembly errors.
The importance of planning for litigation in general and creating the discovery system in particular has many similarities to building a house. A litigation plan could be simply designed as well but just like the house building analogy, a simple litigation plan, particularly in the age of e-discovery, is a prescription for disaster that will surely cause many disputes, many false starts, and the wasteful allocation of resources.
There are many rules that govern civil litigation in the federal courts. The primary constraint as expressed in Rule 1 of the Federal Rules of Civil Procedure (FRCP) is to, “. . . [S]ecure the just, speedy, and inexpensive determination of every action and proceeding.” The importance of planning in order to achieve that goal is clearly understood since planning is expressly required by the Rules. In fact, a Discovery Plan is required by Rule 26(f)(2) of the FRCP.
The following sections review the importance of discovery plans and protocols in litigation and how a plan can be used to improve the performance of litigation for cost schedule and performance/quality objectives, how plans are incorporated in Rule 26 of the FRCP, and the eleven steps to designing a discovery plan.
Why Litigation Often Fails
A disappointing outcome in litigation is not determined solely by the verdict. Indeed, one can win the verdict but if it costs more than it was worth it is just losing a different way.
In some cases one never gets to the verdict because a party is able to conclude well in advance that the outcome will not be worth the costs. Even in those cases the settlement may be more about avoiding the punishment of litigation than obtaining a reasonable outcome. The reality is that litigation has become very expensive and one must be willing to take the punishment for the sake of principle.
Although many like to blame the current driver for the high cost of litigation on e-discovery, the true cause is not the nature of the digital evidence, the inherent procedures and processes related to the digital evidence or the use of vendors and consultants who are experts in managing digital data. Rather, the true cause for the high cost of litigation is document review and a failure to follow the rules of procedure as they exist.
According to the 2012 report by the Rand Corp.’s Institute for Civil Justice, 73 percent of e-discovery costs are expended on manual document review at a cost of 15,000 dollars per gigabyte of data reviewed. Furthermore, 75 percent of the data reviewed are useless and will never be produced. More efficient methods of review or selecting documents for review like technology assisted review are not being used and likely because there is a reluctance to forego historical revenue streams that have long been part of counsel’s document review efforts. (see, Selecting an E-discovery Vendor: A Best Value Approach)
The high cost of document review, particularly the excessive expanse of it, is highly related to the second major driver of high litigation costs—a failure to follow the rules. Since the 1970s there has been considerable discussion and criticism within the legal profession regarding discovery abuse. The rules of procedure have been changed numerous times to try and encourage both cooperation as well as promote the “proportional” use of discovery in order to deliver, “the just, swift and inexpensive determination of every action and proceeding” as promised under Rule 1.
What tends to happen is that the parties do not cooperate. They do not cooperate in planning litigation nor do they cooperate in following the rules regarding any number of subjects like preservation and production just to mention two. Some have suggested that these failures are due to confusion about the definition of “zealous advocacy” and that the profession’s members do not realize that “zealous advocacy” means arguing about the facts and not about hiding them. As a result of the latter, however, litigation costs skyrocket.
Not only has this problem been recognized and addressed by various procedural rule changes over the last 35 years, it has been the subject of numerous other sources as well. A few of the other sources are the following.
- commentary by the Sedona Conference
- Cooperation Proclamation (2008),
- Cooperation Guidance for Litigators and In-house Consel (2011),
- Cooperation Proclamation Resources for the Judiciary (2014);
- studies like the 2008 interim report by the American College of Trial Lawyers and the Institute for the Advancement of the American Legal System; and
- numerous case decisions like
- Mancia v Mayflower Textile Services, Co., 253 F.R.D. 354 (D. Md. 2008) and
- National Day Laborer Org v US ICE, 2011 WL 381625 (S.D.N.Y. 2011).
A lot of the above writings attribute the failure to cooperate to a misunderstanding of the adversarial nature of the litigation process. They point out that a lawyer's ethical duty for zealous advocacy means arguing about the facts and not about hiding them. Thus, cooperation, particularly when planning discovery, is also part of their ethical duties and it is not inconsistent with any other ethical duties that they owe a client.
How Systems Engineering Improves Planning for Complex Projects Including Litigation
When one thinks about a plan, one often thinks of it like a map or a recipe. In other words, one typically thinks of a plan as a set of instructions or as a procedure or method of acting in order to achieve a particular outcome.
In traditional planning approaches the focus of the plan is on production. The planning and design phases are less rigorous and the flaws of the initial plan might only be recognized when production itself fails.
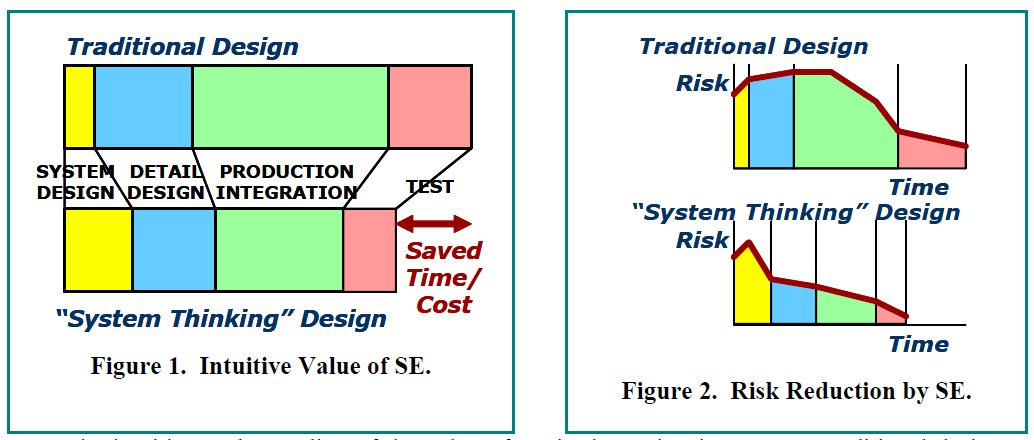
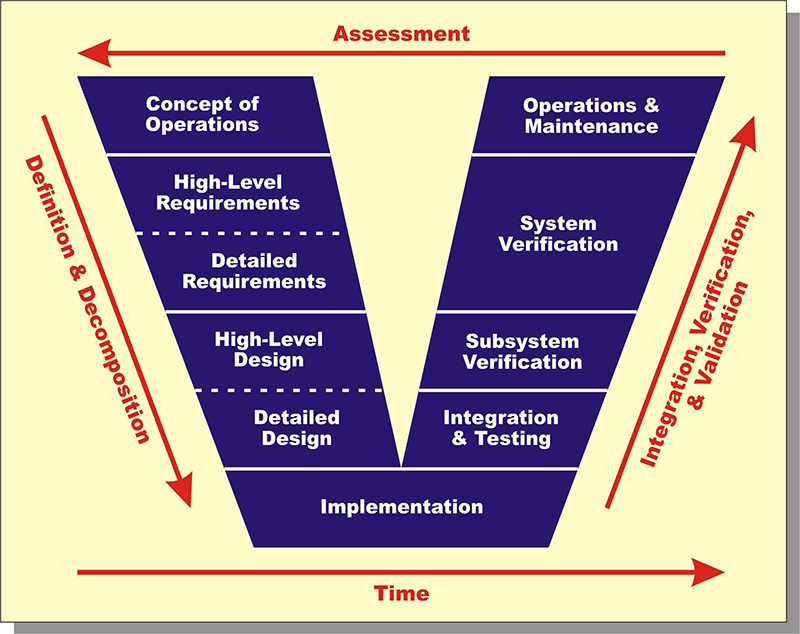
Systems engineering takes a more thoughtful approach to plan development. Perhaps the most significant difference is that the thoughtfulness is moved forward in the development process in order to avoid wasteful production failures. In the process it improves problem decomposition and definition, requirements synthesis and then recomposition and process development as illustrated by the classic "V" diagram below. The result of more thoughtful planning, however, is that there are fewer production failures requring system redesigns and the overall project takes less time with less cost as shown in Figure 2 above
As a result, while developing the plan the actual objectives are sharpened as one evaluates decisions and the effects of trade-offs between the cost, schedule and performance/quality criteria. It does this in several ways.
First, the process of developing the plan provides the parties a means to determine their desires. It may be easy to say that one wants to build a house but by following systems engineering techniques to problem definition and decomposition one can better determine what that means. For example, will it be a one story house or two? How many bedrooms and bathrooms will it have? Clearly it would be better to define these requirements before production begins and resources have been allocated and expended.
The development of the discovery plan and protocol provides similar assistance to the litigation. The issues of liability, causation and quantum were likely expressed in the pleadings. The plan will become more specific and identify which people, places and events are likely relevant to the issues and to what extent computerized devices and storage media should be examined for relevant evidence. With e-discovery this particular step can have significant consequences since there are typically lots of different devices and storage systems that could potentially store important evidence.
Second, when developing a plan, there are considerations of more detailed trade-offs and alternatives that are performed in order to further optimize the design for cost, schedule and performance/quality. When building a house these kinds of trade-offs and requirements synthesis can include decisions regarding things like carpet or hardwood floors, exterior brick or wood siding, asphalt shingle roof or metal roof just to mention a few.
In litigation there are similar kinds of trade-off decisions that can be made. They cover a wide range of subjects like the following.
- Should the data productions be done in native format or converted into image formats?
- Should all exchanges include processed results such as format conversions, text extractions, internal metadata extractions or should each party be responsible for developing its own value added data from whatever data is actually exchanged?
- Should the exchanged data include various field attributes and what should those be?
- What attributes like file system attributes, message attributes, or keyword attributes to mention a few should be used to decide what data will be exchanged?
Third, during development of the house plan there are often tests performed to confirm performance capabilities of materials, parts or subassemblies. More complex tests can be used to demonstrate proof of concept before actually proceeding with a design concept. In addition, prototypes can be constructed and tested to confirm whether the design meet the desired performance criteria prior to committing the huge resources and beginning full scale production.
In litigation various types of early case assessment techniques can be used to probe the data population in order to identify patterns in the data, validate expectations of its contents, identify gaps in the data, or highlight unexpected occurrences. Even more substantial analytics like computerized search techniques can be used to test concepts and validate the quality of the data and whether it is relevant to the issues in the case. A multi-stage approach can be used to prototype and validate processes and procedures prior to final acceptance of the plan and more fully committing resources for full scale document production.
Fourth, after problems are decomposed and requirements synthesized the outcome and lessons learned are recomposed into a final design and interfaces between the various parts identified so that the final outcome will work as intended.
In litigation, the recomposition of the requirements result in the design of the production requests that will result in the actual production of the desired documents for review and use at trial.
Clearly the systems engineering approach incurs more analysis and evaluation on the front end than traditional methods that target an early start to production. While the traditional approach may initiate production sooner, it inevitably results in a longer project performance period and higher costs as a result of unforeseen problems that sidetrack progress and consume resources unnecessarily.
A systems engineering approach is not only more thoughtful it is more formal as well. Once decisions are made they are documented and managed by way of configuration and project management tools. These disciplines also provide at least two other advantages.
First, during project performance the documented plan provides a means to measure progress on a cost and schedule basis. Once differences between the plan and actual performance are detected, corrective action can be taken before the consequence of mistakes or errors can magnify into even larger problems.
The other advantage of having a documented and controlled management plan is that when differences do arise between the plan and actual performance, the documented plan can provide a means to test recovery strategies. After all, the documented plan should be working model of reality. Thus, by iterating back through the plan and performing additional trade studies and studying the consequence of other corrective measures, recovery strategies can be identified.
How Plans are Incorporated into the Civil Rules of Procedure
While the advantages of good planning have been lost on those conducting litigation, they have not been lost on those creating the rules of procedure which are supposed to be followed by those conducting litigation. The requirement for discovery plans have existed in Rule 26(f) of the FRCP since the 1993 amendments, although discovery conferences have been part of Rule 26(f) since the 1980 amendments when 26(f) was first added.
The discovery conference was added in 1980 in an effort to curb discovery abuses. At that time, however, the discovery conference was simply something where counsel could request the assistance of the court if counsel had been unable to agree on a reasonable discovery plan.
Since few had utilized the use of discovery conferences, the 1993 amendments required the development of a discovery plan so that it could be incorporated into the court’s scheduling order under Rule 16, which is one method for how the court manages the case. The 1993 amendments even described certain matters that should be addressed by the parties and included in the discovery plan for inclusion in the court’s scheduling order.
The 2006 amendments to Rule 26(f) made it clear that the parties were to discuss the discovery of Electronically Stored Information (ESI) during their conference. Actually, the discovery of computerized data had been “black letter law” for more than a decade prior to the 2006 changes. (see, Anti-Monopoly Inc. v Hasbro, Not Reported in F.Supp., 1995 WL 649934 (S.D.N.Y.)) In fact, the term Electronically Stored Information (ESI) had been used more than 20 years prior to the 2006 changes when it was decided that, “It [was] now axiomatic that electronically stored information is discoverable under Rule 34 of the Federal Rules of Civil Procedure. . . .” (see, of Bills v Kennecott Corp., 108 F.R.D. 459, 461 (D. Utah 1985)) Thus, in many respects the 2006 amendments were simply formalizing what was already an accepted practice in order to end wasteful motion practice as a result of failures to cooperate that claimed the contrary on almost every case where computerized data were sought in discovery.
The 2006 amendments to Rule 26(f) even embellished the subjects to be discussed at the discovery conference and included in the Discovery Plan. The Committee comments to the 2006 changes to Rule 26(f) also referenced section 40.25(2) of the Manual for Complex Litigation that listed a number of preservation subjects that should be discussed during the discovery planning conference.
The 2015 amendments also made some editorial changes to the discovery plan section of Rule 26(f) to include a reference to preservation as a topic for discussion and a reference to Court Order under Rule 502 and the party’s discussion of how privilege material will be handled. Like many of those preceding it the 2015 amendments to Rule 26(f)(3) that expressly included preservation as something to be discussed in the discovery conference were nothing new, since the Rule 26(f)(2) had already suggested the discussion of preservation during the discovery conference so that it could be included in the Scheduling Order.
Discovery Plans are required by Rule 26 of the FRCP. In fact, a Discovery Plan or protocol is the product of the Discovery Planning Conference required by Rule 26(f)(2). Rule 26(f)(3) identifies a list of items that should be addressed in the discovery plan. As of the 2015 amendments, those items are:
- 26(f)(3)(A)
- Timing, requirement or form of initial disclosures, and
- Statement when disclosures will be made
- 26(f)(3)(B)
- Subjects on which discovery may be needed,
- When discovery should be completed,
- Whether conducted in phases or limited or focused to a particular issue
- 26(f)(3)(C)
- Issues about
- Disclosure,
- Discovery or
- Preservation of ESI,
- Form of production
- 26(f)(3)(D)
- Claims of privilege,
- Protection of trial preparation materials,
- Requests for protective orders
- 26(f)(3)(E)
- Limitations on discovery required by these rules or local rules
- Any other limitations
- 26(f)(3)(F)
- Any other orders under 26(c) or 16(b)
One of the ways the court manages a case is through the Rule 16(b) scheduling order. Interestingly, the Discovery Plan provides many of the details that will be incorporated in the scheduling order. Thus, the discovery plan is essential for the court’s proper management of the case.
Just like rule 26(f)(3) lists items that should be included in the discovery plan, rule 16(b) identifies things that should be included in the scheduling order. Since the discovery plan feeds the scheduling order, the items listed in Rule 16(b) should also be considered in the discovery plan.
The items listed in Rule 16(b) as the contents the order are the following.
- 16(b)(3)(A) – limiting time to
- join other parties,
- amend the pleadings,
- complete discovery, and
- file motions;
- 16(b)(3)(B)
- Modify the timing of disclosures
- Modify the extent of discovery,
- Provide for
- Disclosure,
- Discovery, or
- Preservation of ESI
- Include any agreements of the parties regarding privilege or protection of trial preparation materials after production,
- Set dates for pretrial conferences and for trial, and
- Other appropriate matters.
Rules 16(b) and 26(f)(3) are not the only places in the FRCP where subjects for the discovery plan are identified. Form 52 in the Appendix of forms to the FRCP also provides a list of things to consider.
- List of persons participating in 26(f) discovery conference
- The date on which or by which the parties will complete initial disclosures
- The proposed discovery plan
- Subjects about which discovery will be needed
- Dates for commencing and completing discovery including completion of staged discovery where one subject is completed before another,
- Maximum number of interrogatories along with the dates that answers are due,
- Maximum number of requests for admission along with the dates responses are due,
- Maximum number of depositions by each party,
- Limits on the length of depositions in hours,
- Dates for exchanging reports of experts,
- Dates for supplementing disclosures and responses under 26(e) to supplement or correct for any material fact or omission unless already made known to the other parties.
- Disclosures under 26(a),
- Responses to
- Interrogatories
- Requests for production or
- Request for admission.
- Other items
- A date if the parties ask to meet with the court before a scheduling order
- Requested dates for pretrial conferences
- Final dates for Plaintiff to amend pleadings or join parties
- Final dates for the defendant to amend pleadings or to join parties
- Final date to file dispositive motions
- State the prospects for settlement
- Identify any alternative dispute resolution procedures that may enhance settlement prospects,
- Final dates for submitting Rule 26(a)(3)
- Witness lists,
- Designations of witnesses whose testimony will be preserved by depositions, and
- Exhibit lists.
Clearly the lists of subjects found in Rule 16(b), 26(f)(3) and Form 52 provide quite a list of subjects that should be addressed and included in the Discovery Plan and protocol. Many are milestone dates while others are more substantive issues such as preservation and discovery or production of ESI. Of course, even some of the milestone dates like dates for exchanging expert reports and commencing and ending discovery require consideration of the efforts required to accomplish those tasks before realistic dates can be developed. After all, it is simply impractical to set an arbitrary date for the completion of discovery without consideration and detailed planning of the processes that must be performed in order to complete that task.
Also, based on the various subjects appearing in the lists of things to be covered by the discovery plan like depositions, interrogatories, request for admissions and form of production, it is clear that the requirements of other rules must also be considered. So, the discovery plan requirements are not strictly limited to consideration of the subjects identified in Rules 16 or 26 or Form 52 without also considering the requirements of the rules governing the efforts referenced in the subjects to be included in the discovery plan.
Under 26(f)(1), the discovery conference, which produces the discovery plan, is to be held as soon as practicably but at least 21 days prior to the Scheduling Conference or a scheduling order is due under Rule 16(b). Under the 2015 amendments, the scheduling order is due 90 days after any defendant has been served with a complaint or 60 days after any defendant has appeared. Thus, there are 69 days within which to commence the discovery conference. The report itself is due within 14 days of completing the discovery conference.
While the order is to be issued within the prescribed period, that period can be extended under Rule 16(b)(2) for good cause. In addition, the schedule can be modified for good cause as well under Rule 16(b)(4).
None of the rules discuss how to progress or complete the discovery plan when the parties cannot agree on a particular subject. In addition, there is no requirement that one party must capitulate to an unreasonably intransigent party that fails to participate in good faith.
If the lack of agreement on a plan is the result of one party’s lack of participation then Rule 37(f) permits the court to impose monetary sanctions on the failing party for any increased costs caused by the failure. Also, at least one case resulted in dismissal in part because of a failure to cooperate as required under Rule 26(f)(2). (see, Siems v City of Minneapolis, 560 F.3d 824, 826-27 (8th Cir 2009))
Also, Form 52 suggests that separate paragraphs or subparagraphs be used when completing the written discovery plan and the parties cannot agree on an item. Once submitted to the court, such variances should be clear notice that judicial action is needed.
Section 11.42 in the Manual forCcomplex Litigation describes a process where judges are supposed to be active in case management. For example, it says that, “
Judges should ask the lawyers initially to propose a plan, but should not accept joint recommendations uncritically. Limits may be necessary even when regarding discovery on which counsel agree. The judge’s role is to oversee the plan and provide guidance and control. In performing that role, even with limited familiarity with the case, the judge must retain responsibility for control of discovery. The judge should not hesitate to ask why particular discovery is needed and whether information can be obtained more efficiently and economically by other means.
Despite the above, judges are not always proactive in case management. More times than not they tend to be reactive and respond only when there are complaints about the process by the parties. Surely, submitting discovery plans with divergent paragraphs when the parties cannot agree as suggested on Form 52 should signal the judge that his input is needed.
Eleven Steps To Designing a Discovery Plan: A Systems Engineering Approach
As described previously, systems engineering takes a more thoughtful approach to plan development. Perhaps the most significant difference is that the thoughtfulness is moved forward in the plan development process in order to avoid wasteful production failures. In the process it improves problem definition and decomposition, requirements synthesis and process development. As a result, while developing the plan the actual objectives are sharpened as one evaluates decisions and the effects of trade-offs between the cost, schedule and performance/quality criteria.
As described in the following eleven sections systems engineering techniques can be blended with the various subjects identified in the rules for developing a discovery plan and accomplishing the objectives of Rule 1, for the "just, speedy and inexpensive determination of every action and proceeding."
1. Determine the Scope of Discovery and the Order of Production
One of the first steps is always to identify the target of discovery. Rule 26(f)(3)(B) identifies the subjects of discovery and whether discovery should be conducted in phases as elements to the discovery plan.
Often the concern is that the subject of discovery is too broad and that examining every computerized device and source of ESI is simply not practical. The parties are in litigation in order to settle their grievance but they are unsure exactly how the process will solve their problem. In large respects, therefore, they are shooting in the dark to discover what facts can settle their problem.
If one of the party's is General Motors, it is not practical to request all of their computer records. Consequently, the first step in any discovery matter is to determine the scope of discovery. Perhaps the best way to determine the scope is to identify the significant people, places and events that are important to the case so that discovery can be appropriately targeted.
The parties and their counsel should, of course, meet to discuss and define the scope of the litigation or they could schedule phone conferences for this purpose. At the same time, it may be useful to even stratify the population and develop a multi-stage discovery effort. In other words, when identifying people, places and events there could be agreement that the data of certain custodians at certain locations involving certain events are expected to have greater significance than others. This determination can then be used to prioritize the discovery.
Prioritizing the discovery can have different significance depending on the situation. The first is simply the order in which media related to people, places and events should be processed and produced. The other, and perhaps more useful, is the actual stratification of the people, places and events so that their respective data can be processed and produced under a multi-stage discovery plan.
A multi-stage plan is actually contemplated in the rules in recognition that it may be better to process and produce the low hanging fruit first while leaving the more difficult and more costly data to process and produce for later in discovery, if even needed at all.
The multi-stage plan provides several other benefits, as well. First, there is likely little need to process and produce documents from low priority data sources, particularly if critical information has already been found. Even when critical information has not been found that could be the signal that there is even less value in processing and producing data from even lower priority data sources.
The second benefit provided by a multi-stage discovery plan is that the separate stages provide the parties with opportunities to prototype the procedures and processes and validate their effectiveness before committing to full scale production. So, proving the validity of the discovery procedures on smaller data populations could save substantial sums down the road, particularly should it become necessary to revise any of the various procedures.
The final benefit is that establishing an order determines the flow of the data and the sequence of subsequent discovery. After all, the order of depositions as well as other forms of discovery could well depend on the order of documents produced.
A systems engineering approach improves the overall process and the ultimate outcome through problem decomposition and requirements refinement. During this stage of the discovery plan the parties should focus on refining the problem and what will actually be required to resolve it.
There are many different manners in which multi-stage plans could be implemented. One way involves stratification of key players versus lesser and lesser players. Another involves highly duplicative data sources like backup tape archives. In that case the various stages could be based on perceived likelihood that critical information will more likely be found on certain media. If so, then perhaps the remaining media could be avoided all together.
Another of the guiding factors to consider when identifying people, places and events should be relevant evidence. A review of people, places and events may not only narrow the scope but further consideration may even narrow the scope within those categories because what is really of interest is relevant evidence and not just data to collect, process and produce. After all, litigation is not an exercise in data processing, review and production skills. Rather, the action will succeed or fail on the basis of a few exhibits. The ideal situation would be to only process, review and produce the data that will be used as exhibits at trial.
Re-openers can be included in the plan so that if during discovery additional information is learned the scope could be expanded. Of course, if the additional information suggests a narrowing of the scope then the additional steps need not be executed, although a formal modification could be executed.
2. Preserve the Data
The second step involves the preservation of the data for subsequent discovery and analysis. Rule 26(f)(3) requires the parties to discuss any issues about preserving discoverable information and include those in the plan.
Preservation is probably the most important part of the litigation since if done improperly a party can lose before the case even really begins. After identifying people, places and events in the previous step, one should also identify the related computer resources, devices and media. Each of the parties could come to meetings or conferences with a map of their own devices and systems. Those maps could be exchanged and discussions held so that the parties can have comfort of the preservation considering their agreements about the scope of the discovery. Thus, the meetings would essentially finalize the data maps that each brings to the discussions.
This is a good task in which to have an expert participate as well as the parties' respective system representatives (a 30(b)(6) caliber of individual). The expert could assist not only in performing the preservation but in helping to scope the universe of media to be preserved. The kind of expert should not just be someone with preservation experience but someone with systems experience, as well. Someone that will know how things work and know what kind of questions to ask about systems and devices based on an understanding of the case and the types of activities in which the parties are engaged. In fact, with the maps exchanged it is the kind of thing that the lawyers could take a back seat and allow the experts and designated individuals discuss to develop the final "map". Once developed the lawyers could ask their own questions to confirm how well the map fits with the planned scope of discovery.
The focus of the preservation effort should be the media, such as hard drives and backup tapes, on which the believed important data resides based on the identification of computer resources used by people and places for the events identified in the previous step. Of course, the parties should have already performed their preservation long before the discovery conference or development of the plan. So, what should be addressed in the plan is confirming the devices and media that have already been preserved as well as identifying those devices that have not already been preserved but are part of the people, places and events previously identified in step 1.
It is important that the media be preserved and not just specific files or documents saved as is common in a targeted data preservation. Rather, it is essential to capture the entire media with the full spectrum of data. That way no matter how the case dynamics might change, the data will be available for analysis.
The importance of preserving the media is not just a technical evidential issue. Indeed, it is an economic issue as well. Determining what specific files are important to a case and should be preserved can take time. In fact, determining what data should be preserved could take more time than just preserving the media itself.
There is a difference between preservation and analysis. A targeted data acquisition that tries to capture files of interest crosses the line from preservation into analysis. Since a party may have a duty to preserve but not have a duty to produce, a key element in minimizing costs is to not waste effort trying to figure out what data on a particular media is or could be relevant and what data is not once the universe of data to be preserved has been determined.
In addition, there are a lot of data hiding techniques that will not be easily uncovered during a targeted data preservation. For example, an important document could have had its file name and extension changed to something outside the types that have been targeted for preservation. If that has happened it will not be selected for preservation and totally missed.
Another reason for preserving the entire media is that if something ultimately has evidential value it will need to be authenticated. Part of that authentication should include the authenticity of the media from which it was harvested. Authentication of the media typically involves examination of the media's system metadata. If the metadata indicates that the media has been doctored or counterfeited then the authenticity of the evidence should be questioned.
In recognition of the above, the plan should adopt media based preservation. The parties should meet to determine what has already been preserved and identify any additional media that should be preserved.
It is not necessary that every bit of data be preserved particularly when there could be several different copies of it. For example, if a particular device is captured through normal backup systems then it may not be necessary to also perform an additional preservation of that device's actual media. The backup history could be far better than any current period media preservation.
Part of the discussion should also involve the particulars of the preservation method. If a media based preservation was performed was it a forensic grade preservation capturing the entire media or was it something that captured only the active data. In the case of the latter the parties may agree that an additional forensic image also be made of the data.
Whatever the parties decide regarding the specific data that has been preserved or will be preserved should be formalized in the discovery plan. Since it is not necessary that all preserved data actually be analyzed or produced, the determination of what data sources should be preserved is not based on which will be analyzed or produced.
3. Schedule of Discovery
Other sections of the plan address quality and cost issues. This portion of the plan should address timing of the work by creating a schedule that includes, at a minimum, the various milestone dates identified in Rules 16(b), 26(f) and Form 52 such as the following.
ITEM |
Rule 16 |
Rule 26 |
Form 52 |
Date for initial disclosures |
X |
X |
x |
Date when discovery starts and ends |
|
X |
X |
Date when each Discovery phase will start and end |
|
X |
X |
Date for joining other parties |
X |
|
X |
Date for amending pleadings |
X |
|
X |
Date for filing motions ends |
X |
|
X |
Date for modifying extent of discovery |
X |
|
|
Date for pretrial conference |
X |
|
X |
Date for trial |
X |
|
X |
Date for proposed discovery plan |
X |
|
|
Date for exchanging expert report |
|
|
X |
Date for supplementing disclosures and responses |
|
|
X |
Date for Interrogatory responses |
|
|
X |
Date for Document production |
|
|
X |
Date for admission responses |
|
|
X |
Witness lists |
X |
|
|
Designation of witnesses |
X |
|
|
Exhibit Lists |
X |
|
|
Schedules are used for planning and managing all kinds of complex projects like building construction, product development, system development and even movie production to not only plan performance and what it will take to accomplish a particular objective but to monitor performance as well. Schedules are even used in litigation and incorporated in the scheduling order but litigation schedules are typically very different than the schedules used in other complex projects.
Litigation schedules are more like milestones where goal accomplishment is tagged to a certain date. By comparison, schedules in the other complex projects mentioned above are typically networked schedules. In network schedules the individual tasks that will be required to accomplish a particular milestone are linked to each other based on their known dependencies. As a result, as work is performed and the schedule updated the consequence of actual performance on the accomplishment of milestones can be calculated.
Litigation schedules, at least those used by the parties to manage the project, should be networked in order to accurately model reality. Depositions can be linked to related document productions that must be related to their selection and processing and even to their initial preservation. There are likely other tasks as well whose performance is dependent on other tasks that precede them.
Multi-stage approaches can provide several issues as well. First, the multi-stage approach may simply have been selected as a means to test production procedures on smaller populations prior to moving to full scale production. Those situations could be fully scheduled using a networked approach.
The other situation, where a multi-stage approach is adopted as a means to potentially avoid portions of the data production that are suspected of having less significance, is more complicated. In those cases, the schedule would essentially be incomplete and dependent on certain events triggering that performance.
Dependencies are not the only characteristic of an accurate schedule. Network schedules should also integrate the resources required to perform a task. Those resources can have availability constraints as well as performance capabilities that influence timing. For example, before document review can begin there must be reviewers and they are only capable of reviewing those documents at a certain rate. Thus, performance constraints are not just limited to task dependencies but to various kinds of resource constrains as well.
Once the resources have been linked to tasks the costs of those resources can be linked as well. Once that is done both elements of cost and time can be calculated.
Typically counsel has to provide clients with time and cost estimates as well as periodic updates on actual performance of the litigation. Networked schedules with integrated resources are a great way to provide clients with that information. Clearly, litigation schedules are not only an interest to the court but to clients as well and counsel on both sides of the litigation serve those masters. Consequently, not only should schedules be incorporated in the discovery plan development but they should be networked schedules with integrated resources as well.
Including realistic cost and scheduling techniques into the discovery plan should not be that much of an extra step. Assuredly, clients have already had their counsel prepare cost and schedule estimates prior to even initiating litigation. If those disclosures were realistic there likely will not be much difference between what was initially prepared from what is prepared during development of the discovery plan with opposing counsel. If there is a significant difference this would likely be a good time for the client to find out. In addition, those interested in settlement are likely very interested in developing a realistic cost and schedule model and doing so with opposing counsel just so the adverse party can accurately assess the cost of such a venture and then calculate their own return on investment.
It is not essential that the two sides share their cost estimates when developing their network schedule. One side can likely be confident that if a realistic schedule is developed that someone else will be able to fill in the numbers and calculate the costs for the client.
Developing realistic network schedules are not cost prohibitive. Simple cases will have simple solutions with simple schedules. The associated cost will be minimal, therefore.
It is the complex cases that will have complex solutions and complex schedules. In those situations the risks are very large. Small errors can have significant consequences. The effort related to spoliation motions and hearings can run hundreds of thousands of dollars even before their outcome is imposed, if successful. Disputes about production format and accessibility can also be considerably large. Rambo style lawyer tactics can boomerang with significant consequences. In essence, it is easy to get off track, particularly when the discovery plan is ill-conceived from the start. Developing a realistic network schedule is a good way to avoid those kinds of problems or at least calculate their consequence before settling on a litigation strategy.
Remarkably network schedules are not just barometers of bad news. Since they are working models they can also be very useful in developing recovery strategies should the wheels come of the bus, as they say. As working models, network schedules can be used for gaming, what-if analysis and trade-off analysis both when developing strategy alternatives and trying to recover from some kind of unexpected event or blown estimate.
Schedule information is often required in complex projects for reasons other than management. Indeed, meeting performance objectives is often very important to any contractual relationship. As such, when performance fails to meet contractual requirements it is often important to understand the cause and which of the parties is responsible. Network schedules are often used for this purpose and often are the kind of evidence required for one party to obtain compensation from the other for performance failures like failing to follow the discovery plan or the rules themselves.
4. Validate the Population
There is an old saying in the technology world about "Garbage in. Garbage out." In litigation, it is simply foolish to commit resources and proceed with discovery if there are significant omissions in the population, or perhaps worse something even less accidental, that if known would have altered the direction of discovery and the allocation of resources. After all, if one is looking for a needle in a haystack, one at least wants to have the right haystack and have some comfort that the needle is still there; otherwise, it is a lot of wasted effort.
Similarly, if one has limited ammunition, one shoots only at verified targets and not blindly into the darkness. Using the home building analogy once again, it is better to wait and purchase the building materials once the construction plans are known; otherwise, it could just be a waste of resources.
Before committing resources to process and review documents it only makes sense to validate that the media from which they come is worthy of that commitment. After all, there will likely be many different data sources but are they all worthy of consideration? Are some likely to be more worthy than others? Would the worthiness of certain storage media change if it was known that it did not cover the period of interest, the custodian of interest during the period of interest, or if it showed signs of deliberate manipulation? Even if all of the media are valid, would some media still have a higher probability of producing relevant evidence than others and would decisions about the allocation of resources and their timing be different if that information was known?
While counsel typically does not like to "investigate" its client, validating that the population of preserved devices is something that both sides should want to have performed, at least on the opposition's preservation. Of course, to avoid later claims of spoliation they should be proactive and validate their own client’s holdings. There are several areas of interest when validating the population of preserved devices and data.
- Whether there have been any other storages devices like external hard drives or flash drives that were attached to bootable devices like personal computers but not preserved that could have relevant evidence?
- Whether bootable devices are the original device for the period in question or was there another hard drive or an earlier hard drive that has not been preserved?
- Whether there are other network attached devices that could have been used to store data and whose contents need to be included in the preserved and potentially producible data?
- Whether the attached storage devices that have been preserved were attached to any other bootable devices other than those that have been preserved?
- What files have been used from bootable devices and are those files on storage devices, including web based storage sources, or media not covered in any of the above?
Although the parties could agree for the examination of their electronic media for these purposes by an independent expert or by their own experts, it is also possible to answer these questions without having to examine the devices themselves. Instead, there are certain system files on the bootable devices that could be produced as part of discovery and those files could be examined to answer the questions about what devices have been attached and whether the bootable device's media appears legitimate.
The particular files that one would want to examine depend on the type of bootable device. In other words, is it Windows or is it Apple, for example. For Windows systems the files of interest are generally several Registry hives. For Apple machines is it several Property List (PLIST) files. Even after identifying the type of bootable device there could still be differences between the operating system versions on those devices that could affect the particular files that will be of interest.
Answering the first two questions above is easily accomplished by requesting the same system files on bootable media. The other questions above could also be answers but there are different files and it is not as simple as a "look" at a few files on bootable devices. Nonetheless, the information is easily obtainable with file system and file pointer kinds of analyses. Consequently, it still is something that the parties would likely want to confirm before "wasting" valuable resources on incomplete, or potentially worse, questionable data.
In a multi-stage discovery plan the parties could defer confirming devices in the lower priority strata until it actually looks like they will be examined. Assuming the first stages are related to more important and likely productive targets, validating the population of preserved media for those strata should be done early.
With respect to other network attached storage there are a couple of different places where one could look in order to make that determination. The "look" is a little more involved than just a couple of files, however.
Once again, both sides have an interest in validating that the population of potentially producible documents is complete. Hence, both sides should want to embrace this effort and include the correct process in their discovery plans.
5. Prepare Data for Analysis
It is hard to make good decisions if one does not have good empirical data on which to base those decisions. The purpose of the data preparation phase is to transform the preserved data into something that has its useful characteristics revealed and available for analysis. In addition, the preparation phase puts the data into a usable form for efficient analysis by automated tools.
The information derived during preprocessing will be used by the parties to make decisions about their own data holdings. They can also share that information, or portions of it, when developing their discovery plan to better plan the particulars of the discovery such as the document file types of interest and the most efficient data sizes for review and production batch volumes. The more buy-in that each side can negotiate into the plan the less likely that there will be a dispute about a particular process employed later on during the actual execution of discovery.
The traditional document review platforms are not the best tools for performing this kind of analysis. In fact, there are many other tools that provide these kinds of capabilities like many of the computer forensic tools and third party specialty applications. Furthermore, they can do it straight from the preserved data without having to extract it, convert it or spend other budget resources. Thus, there are economic reasons for using these special kinds of tools and avoiding the document review platforms until after the desired documents are actually selected.
The kinds of preprocessing should be formalized in the discovery plan. It may not be possible to complete the data preparation prior to completing the discovery plan, although it would be ideal if the results were known and could be used for developing the entire discovery plan. The reality, however, particularly in a multi-stage discovery plan where hopefully not all stages will have to be performed, is that data processing will not be complete and the discovery plan is flexible enough to adapt to whatever situations and conditions are found as the actual production moves forward.
Systems engineering is frequently an iterative process of decomposition and synthesis followed by recomposition and integration of the result. While it is always possible that things will work on the first attempt, it could very well be that further follow-on is required.
Both sides have an interest in memorializing the data processing efforts in the discovery plan. Primarily, it guarantees that certain minimum standards will be followed by both sides. In fact, both sides have an interest in obtaining agreement on the minimum standards to avoid having an entire effort torpedoed due to faulty shortcuts or errors and omissions in performance, particularly after having incurred considerable expense.
When proceeding under a multi-stage discovery plan it is not essential that all of the data be subjected to data processing prior to finalizing the discovery plan. Rather it is possible to only subject the media selected for a particular stage or even stages to the analysis. With each stage the results can be updated and compared against prior groupings.
When developing a plan the parties can agree to what extent the data will be subjected to these processes prior to production. The facets that they should consider are discussed in the sections that follow.
Compound Documents Parsed and Cataloged at Desired Levels of Granularity
Many of the document types sought by litigators are not simple documents but rather are compound documents. A spreadsheet is a potential example of a simple document. On the other hand, an e-mail is an example of a compound document. E-mails have both a message and they have attachments; hence a compound document. A compressed archive or zip-file is another example of a compound document since it contains many documents within it.
When selecting files for review or production it is essential to identify the contents of compound documents so that they could be included for consideration. Thus, one thing that should be considered in the profile is the granularity of compound documents. In other words, at what level will they be decomposed in order to ensure that their contents are properly included for consideration.
Another important consideration is the effect of granularity on deduplication. The most place where this is most important involves e-mail. In other words, should duplication be performed at the entire e-mail level (message and attachments) or at each element (message and each attachment separately)?
If the entire message level is chosen then the same message will be seen each time there is a different date, or distribution list or attachment. Similarly the same attachment will appear each time it is attached to a different e-mail as well as saved to different locations on the server or personal computer.
If the purpose of the deduplication is to remove redundancies like those that exist in multiple backup tapes then deduplication at the message level is adequate. If the purpose is to develop the most efficient data set for document review then greater granularity is desired.
If the same message is sent to two different people on different coasts each of those messages will have different hash values even though they contain the same message and attachments. The difference is caused when the message travels the internet and receives date stamps at each server along the way. The message's route to one coast will likely be different than it's route to the other coast. Of course, the original message will never have traveled the internet and not have any server date stamps.
Thus, in order to develop the most efficient list of documents for review and to ensure never reading the same e-mail more than once, the deduplication should be done at the most atomic level. Even then, since the message is actually a collection of metadata fields only certain fields about the message should be selected for deduplication.
Again, consider the case where a message is sent to a distribution list and then after sending it one realizes that someone was omitted from the distribution so it is sent again to those that were omitted. In order to avoid seeing that e-mail more than once and in order to develop the most efficient lists of documents for review only the data stream comprising the message portion of the e-mail should be selected for hashing and deduplication as well as the attachments separately.
Thus, for efficiency sake as well as other objectives like completeness the parties should decide the level of granularity for determining deduplication. To some extent it could be left for each of the parties to determine granularity for their own purposes in order to achieve the greatest efficiencies. On the other hand, each of the parties has a stake in efficiency at the production level when trying to minimize production costs.
Hashes Calculated
Since it is well recognized that the volume of electronic data will be significantly large one of the key tools that the litigants will require to conduct efficient discovery is a means to identify and remove the duplicates. Removal of duplicates should not be performed based on file name or subject matter or other visible characteristics of the data. Rather, the best method for identifying duplicates is through the use of digital signature or digital fingerprint algorithms.
The MD5 message digest (MD5 Hash) was developed in 1994. It is a one-way hash algorithm that takes any length of data and produces a 128 bit "fingerprint" or "message digest".
The MD5 algorithm was intended for digital signature applications. At 128 bits the number of potential outcomes of the MD5 message digest is 2 to the 128th which is larger than 3.40282 x 10 raised to the 38th or the number 340282 followed by 33 zeros, which is larger than a trillion, trillion, trillion. It is believed that this number of unique outcomes is so large that it is highly remote that two different messages would have the same MD5 message digest.
In the event that the MD5 algorithm does not provide a low enough probability that two documents would produce the same message digest then there is also a SHA-256. This algorithm is 2 raised to the 256th or 1.157 x 10 raised to the 77th or the number 1157 followed by 74 zeros which is about twice the number of possible outcomes as the MD5.
Thus, either the MD5 or SHA-256 algorithms can be used to determine a signature of all electronic documents comprising the population of those that are discoverable. From that population, the unique documents can be identified based on their message digest values.
Furthermore, the fingerprint is "non-reversible". In other words, it is computationally infeasible to determine the contents of the input file based on an MD5 hash value.
When performing the deduplication process there are two elements that requesters and producers will want to determine. The first is the granularity at which the deduplication will be performed. After all, the purpose of the de-duplication exercise is to reduce the population of documents in order to streamline the litigation lifecycle and reduce review time and analysis time and costs. How granularity can affect this process is described in a subsequent section.
The second issue is how to treat and track the duplicates since the existence of these duplicates could have significance to the case. Thus, while identifying and removing duplicates is important for efficiency reasons, knowing that duplicates exist and where they are located could be very important when understanding how those documents were used is important.
In a multi-stage discovery plan, it is possible that as the discovery is expanded to each group that the number of unique files will diminish from grouping to grouping because they have already been considered in earlier stages, although the tracking of where each of the duplicates was found will need to be updated.
Signature Analysis
Electronic media can have many different types of files stored on them. In e-discovery parties are often interested in only certain types of files and not necessarily all of the files on a media. Generally, people identify the file type by its extension. However, in a Windows environment the extension is not as reliable as in other systems. In addition, it is easy for evil doers to change a file's name and extension as a means to disguise a file's significance.
One method of validating a file's true nature is through signature analysis. Essentially, signature analysis looks for certain known markers in the file's internals that identify its type. In fact, software programs frequently rely on these internal markers rather than the file's extension before proceeding.
Signature analysis and confirmation of each file's type should be part of every e-discovery process and included in the plan.
Known Files Identified
In addition to de-duplication, digital signatures such as MD-5 hash can be used to accept or reject the files that are to be considered. In other words, if a particular file is sought, such as a trade secret, then search parameters could be constructed to look only for files with that hash value.
The hash value is not affected by a change in file name, since the file name is not part of the file itself but resides in the filing system. Thus, if the file name was changed as a means to hide its nature, the hash analysis would still detect it.
Hash analysis can also be used to reject or exclude certain files. For example, with each software installation there are often sample and tutorial files to assist users in learning the product. These sample files could well fall within the desired file types when file's are being selected for document review and subsequent processing by their file types.
There are lists produced containing all the known hashes for commercial software packages. These would include the sample files. Thus, if these lists were included in the respondents production process then such files could be omitted from production. Similarly, the lists of known hashes can be used to exclude files from prior searches or analysis, particular when a multi-stage discovery plan was being followed.
Encryption Detection
When planning discovery it will be useful to know which, if any, files are encrypted. Encrypted files cannot be searched since their contents are scrambled and meaningless. Most likely cannot be examined either, although it is possible for the encryption protection to simply be protection against changing the document contents. Thus, it is necessary to know what files are encrypted so that they can be handled properly.
Depending on the volume of encrypted files and where they happen to be encountered the parties may decide to postpone decryption efforts, after all it may be possible to obtain considerable information about an issue from other unencrypted files. In addition, decrypting files will be an added cost to the discovery process. So, accumulating them into groups and processing them on a batch basis will likely be more economical than handling them when encountered.
An entropy test is a means for detecting encrypted files. Essentially, an entropy test measures the chaos within a file. While the test is not foolproof, the more chaos that a file contains the more likely that it is encrypted. Clearly, one of the preprocessing tests should be an entropy test or other similar process to try and spot encrypted files early so that they can be subjected to the special treatment that they require and before the other processes and efforts that will not be effective on them are wasted.
Deleted File Recovery
Consideration should be given to recovering deleted files. There are several different methods by which deleted files could be recovered. There are the traditional methods that recover deleted files from freespace either through file system pointers or by data carving based on file type signature data. Then there are methods that recover files from Volume Shadow Copy (VSC). While the traditional file recovery methods are something that the parties will want to discuss based on particular case circumstances, the VSC data is something that should be performed in every situation.
The VSC was a feature introduced with Windows Vista. It provides a means of archiving files so that they can be recovered later. Thus, VSC files are not really deleted files. Rather they are archived files and they are accessible to the user simply by right clicking on the file in Windows Explorer and then viewing the Previous Versions tab in the Properties Dialog box. Consequently, one could easily argue that the files are "easily accessible" to the user when operating the computer and should be treated the same as other active data files even though they are more technically a file archive.
While VSC was enabled by default on Windows Vista systems it has to be enabled on Windows 7 and later versions. Thus, there is no guarantee that VSC versions of files will exist on Windows based computers that are Windows 7 and later, although it is a good practice for organizations to activate the feature on employee machines, particularly when they implement full disk encryption and want to be able to recover deleted data when the need arises.
While recovering VSC data from a device that is up and running is simple enough, it is a different matter when recovering the data from a detached drive or forensic image. Nonetheless, there are forensic software tools that makes this process very easy and will even identify files in VSC that are no longer in the active file system. Thus, the parties when negotiating their discovery plan just need to make sure that those tools will be used when extracting data from preserved media.
As indicated previously, there are other methods of recovering deleted files than from VSC. These other methods are the traditional techniques that involve file system pointers or data carving based on file signature data.
File recovery software has become quite effective. Furthermore, the use of automated tools makes recovery relatively inexpensive. Unless there are concerns about whether active files contain the needed evidential data, deleted file recovery can be omitted because all that it is likely to provide is temporary versions of currently active files.
If there are concerns about the evidential quality of the active data then recovering deleted files is a real option that is worthy of consideration. The recovery can even be tailored to target on the kinds of files of interest. For example, it could be tailored to target only Office documents for example while ignoring graphical images that could have come from browsing websites.
Regardless of the tailoring, the parties should recognize the there are all kinds of situations where files are deleted. Many are system related. Thus, the deleted files recovered could be temporary versions of active files that were deleted when the active file was saved. Then again, these deleted files could be prior be instances with slight modifications to currently active files or even be files that are no longer exist as active files.
In any event, the parties can discuss the specifics of their case and decide how they want to handle deleted file recovery. Of course, they could always decide to postpone any deleted file recovery effort to some future stage in a multi-stage discovery plan and base their decision on the results obtained from active files.
File System Data Collected
If a storage media can be analogized to a library the file system is like the card catalog while the files themselves are like the books on the shelves. By examining the file system one can identify the files that are currently on the media and of potential interest in the same way that by examining the card catalog one can determine what books are in the library and are of interest.
Just like the card catalog contains certain attributes about the books on the shelves, the file system contains information about the files on the media like the file's name, extension, location, size, and various date stamps. These attributes can be used to select files of interest and also assess whether the media should even be selected for further processing. After all, what might be of interest to the case is files of a certain type, from a certain time and related to a particular user. This kind of information can be readily determined by examining the file system data prior to actually processing any of the files themselves for processing.
Other important information can also be obtained from the file system data. For example, the file system could also still contain entries of files that were deleted, although it is possible that it will not reveal all files that have been deleted. Nonetheless for those deleted files that are contained in the file system there is likely enough information to assess whether there has been a spoliation issue that needs further examination before proceeding with processing and production.
As part of the file system analysis one can also search the media for prior instances of a file system. Finding these remnants can be important particularly if they are remnants from a file system that existed just prior to the preservation or after a duty to preserve had arisen. A lot of data hiding techniques would leave remnants of a prior filing system. Thus, finding these can also signal a spoliation issue that needs to be further examined before proceeding with processing and production.
In light of the above, one of the things that should be done during preprocessing is development of file system information with which to perform various analytics in order to better understand the contents of the various media in order to determine its usefulness to the case and assess what resources will be needed for processing, production and continued discovery.
Although lists are sometimes not informative enough, they, nonetheless, are a good first step that allows the requesting party to see what is available and how their requests can be better targeted. In addition these lists provide useful attribute information that confirm or deny attempted spoliation as well as provide important usage and trend information about the media and the data it contains.
Search indexes constructed
At some point the data will be probed with various kinds of search efforts. These efforts most frequently rely on indexes of document contents. Thus, before the searches can be run the indexes should be constructed.
Of equal importance is from what the indexes should be constructed. There are a couple of different issues that must be resolved about search index creation.
The first is that not all documents are searchable. Documents like images, for example, must first have their contents converted into a searchable form. Thus, one thing that must also be decided is how unsearchable file will be converted into searchable form. Typically, non-searchable documents are converted into some kind of format that can then be optically recognized.
The list of unsearchable document types can be surprising. A PDF document, for example, may not be searchable. In addition , it is hard t know for sure which ones are and which ones are not. Thus, it is often common practice to convert them all and then optically recognize them.
Even document types that are searchable like spreadsheets and word processing documents can still have embedded images. So, decisions should be made about how those should handled as well.
Second, not all search engines can index a document’s internals. In such cases, things like application metadata will be missed. Thus, another decision is the extent and manner in which application metadata will be indexed.
A third consideration is the accuracy level of optically recognized text. Optically recognized text with low error rates can still miss important documents. Thus, it is important to decide at what accuracy level the recognition will be performed.
File activity constructed
Depending on the case the existence of a document may not be as interesting as whether it was viewed. There are several different ways to determine whether a document was actually being opened and viewed. If this is one of those kinds of cases, obtaining the file activity data from various file pointer sources will be useful.
Even if it is not a case where viewing a document is dispositive to a particular issue in the case, it may still be a useful means to narrow discovery to more meaningful documents, at least in a multi-stage discovery setting.
6. Data Analytics
At the end of the day every case comes down to a few hundred exhibits. Many of these may already be known at the time of initial disclosures under Rule 26(a)(1). Still others may still be buried within the data population.
In large part, discovery is about finding the exhibits needed for trial that are buried within the data population. For all practical purposes, however, the effort expended to sift through the larger population of documents just to find these few remaining exhibits is wasted effort. Data analytics is the process intended to reduce the wasted effort of finding these few remaining exhibits.
From a systems engineering approach, data analytics is the techniques for finding the documents without having to examine each one. Systems engineering is an iterative process that starts at the higher level item, such as those expressed in the complaint, and then moves into lower level components and processes with problem definition and decomposition, requirements synthesis and then back up with recomposition of the results into solutions and interfaces. With better clarity about the data population one can devise better document requests that better targeted at the documents that will matter.
As with the data preparation phase discussed previously, the traditional document review platforms are not the best tools for performing this kind of analysis. In fact, there are many other tools, like the computer forensic tools and third party specialty tools that provide these kinds of capabilities and can do it straight from the preserved data. Thus, there are economic reasons for using these special kinds of tools and avoiding the document review platforms until after the desired documents are actually selected.
A big question that needs to be answered is how much of the data analytics if any will be performed prior to submission of the discovery plan and issuance of the discovery order. The reason that this is such a big question is that the data analytics could very well narrow discovery dramatically, since the outcome of the analytic should be a clearer understanding of the documents that should requested and will be produced.
Without the analytics, production requests tend to be quite broad and overly inclusive. With the analytics the parties can have a much greater understanding of the data population both in terms of data volumes and data types and even what documents likely will be dispositive. Thus, there is considerable incentive for conducting the analytics prior to finalization of the plan and issuance of the order.
During the analytics it is not intended that there will be any documents swapped, although in some cases they could be consulted and the details shared between the parties. The intended benefit of the analytics is to obtain considerable insight about the data holdings as well as better identifying which documents are more likely relevant to the issues.
Since relevancy is a highly subjective decision, the analytics provide the requesting party with greater confidence that relevant documents will be produced as part of whatever production requests are ultimately fashioned. As a result, requesting parties can more comfortably narrow their production requests.
Before this kind of substantial information can be obtained there likely will need to be put in place protective orders and non-disclosure agreements, which could be one reason for why the analytics come after development of the discovery plan and issuance of the order.
Even if the analytics are not shared or at least saved until after approval of the discovery plan and issuance of a scheduling order, there is plenty of reason that the data owner will want to conduct its own analytics. In the event of a disagreement over the discovery plan, the data holder can use this information to persuade the judge that their plan for discovery is more consistent with the goals of discovery in the first place and the accomplishment of the Rule 1 objectives. After all, if one wanted to avoid a discovery dispute, the best way could very well be to prepare divergent paragraphs of the plan as suggested by form 52 and then support that position with empirical data derived from analytical testing of the population.
There are actually several types of analytics that should be performed and, of course, under a multi-stage approach there could be several iterations of the process. The kinds of analytics that should be performed are described in the sections that follow.
File System Analysis
The results of the data processing efforts discussed previously are often merged with the file system data by the kinds of tools that provide those kinds of results. The result of those efforts are often lists and tabular reports about the file system contents along with other attributes like hash values, encryption indicators, file signature results.
With this information there are many types of lists that can be used by both sides to identify desired documents for production. By using file system attributes along with other elements developed during the data preparation phase one can tell a lot about a document and if it could be of interest.
Storage location, dates, name, type are just some of the attributes that can reveal much about a document’s desirability. Filtering data sets by these attributes can even be used to stratify the population for use with other selection techniques like content search.
Sharing the results of this analytical information along with distributions like those discussed below can help both parties to streamline a production request and target it for better accuracy and relevance as well as budget and schedule what it will take to more thoroughly review the data.
File type distributions
File type distributions based on the results of signature analysis provide informative information about data population content. The existence of file types of interest can be confirmed as can their quantity. After all, a smaller than expected population of desired file types could raise many questions including authenticity of the media or even spoliation.
The same can be said when file types that were not expected are uncovered. Such types could be added to what the parties had planned to consider.
File type distribution also provide planning and resource information. For example, not all file types are searchable. Thus, file type distributions provide insight about the volume of data that will need additional processing either before or after production.
File type distributions also provide planning and resource information about the population as a whole. The results could alter planned stage sizes, either larger or smaller, when a multi-stage discovery plan is being followed.
Custodian distributions
The parties may have had certain expectations about the volumes of data held by certain custodians. Differences in expectations could again raise questions about authenticity of the media or spoliation. When custodian distributions are further refined by file type or other attributes still other questions could arise.
Of course, authenticity or spoliation are not the only questions. There could be others about resource requirements and the adequacy of plans to process, produce and review documents.
Time period distributions
Time period distributions, particularly when further refined by file types and custodians, are another useful tool when planning discovery and identifying documents of interest.
Other distributions
There are plenty distribution analyses that can be used. Some of the other distributions of interest involve e-mail containers, message senders and recipients, unique versus duplicate files based on hash value.
File Activity Analysis
In addition to knowing what files exist, knowing which ones were actually opened and viewed could be of far more interest. The results of these analytics can be merged with other file lists and distributions to help narrow what documents are of the most interest and should be produced.
Document Search
Obviously some responsive documents will require more sophisticated methods to find. There are a lot of different automated techniques that can be used.
Regardless of the search method used like keywords, hashes, context, predictive coding, etc. one feature that should be included in the plan is that the parties will again share lists of the search results. This provides the parties a means to examine just how effective the search methods are and make changes before going to full scale production.
The lists can be of two types. One type is a simple list of the files that includes various attributes like name, extension, file type confirmed by signature analysis, custodian, path location, various date stamps and hash calculations just to name a few. The report can be provided in tabular form like a spreadsheet so that the parties can perform additional analyses like sorting and filters about the results.
The other type of list is a context list that in addition to the basic attributes about the file includes some context around the selection criteria. The context list is probably better suited to keyword searching and provides a fixed number of words or characters either side of the keyword hit. The context provides the parties a means to assess the effectiveness of the search term and whether the document is relevant or more likely just a false positive.
A context result could also be provided with other search techniques like hash and predictive coding. In those situations, however, the supplied context could be the first 100 words of the document or something similar that again could be used by the parties to assess the relevance of the document.
7. Handling Privilege and Confidential Items
How to handle privileged documents is always an issue to be discussed. It is even one of the items expressly identified in Rule 26. Of course, privileged documents are not the only issue. The handling of confidential data is also something that should be discussed and resolved. In fact, the handling of confidential data is also something that is expressly identified in Rule 26 to be resolved in the 26(f) conference and Discovery Plan.
Naturally, each side will handle the manner in which they choose to find and identify privileged and confidential information. What needs to be resolved is the mechanics of protecting that data.
Handling Privileged Documents
Generally privileged information will be withheld but the particular documents identified in a privilege log. In complex documents it is possible to resolve the issue by redacting the privileged information while producing the remaining portions of the document.
Despite the above, there are several issues that are still up for discussion. For example, with compound documents like e-mails and compressed archives (zip files) what should happen if only one of the documents contains privileged information but the other documents in the collection are not privileged? Should they all be withheld or only the one containing privileged information?
E-mail chains provide another issue for privilege. While a single message that incorporates an e-mail chain is a single document for asserting the privilege, each original message of the chain parts are separate communications. Thus, to protect the privilege under Rule 26(b)(5) each instance in the chain must appear in the privilege log. (see, Properly Logging E-mail versions Key to Maintaining Privilege and Avoiding Sanctions) When creating the plan the parties should make it clear that each message should appear in the privileges log.
Another consideration that can be included in the plan is a clawback agreement. A clawback agreement permits the return of documents without waiver. Generally clawback agreements are used in the context of privileged documents but they need not be limited to privileged documents. In fact, they could be more broadly constructed to permit the return of any document mistakenly produced.
Clawback agreements are an attractive feature intended to keep discovery costs low by minimizing the need for strict document review during discovery. While the agreements are often enforced that is not always the case. Exceptions have been made based on the reasonableness of the procedures employed to prevent the inadvertent disclosure of documents. Some clawback agreements have even been crafted in a way that emphasizes the reasonableness requirement in order to protect privilege. In addition, state law cases have not always followed federal procedures, particularly when waiver protections are more narrowly construed. In any event, clawback agreements are a nice feature for every discovery plan but parties should recognize that they may not be foolproof.
Handling Confidential Documents
The handling of confidential information has many similarities to privileged information, although the issues is not one of non-disclosure but of limited disclosure. As with clawback agreements the parties can negotiate what documents are subject to confidential status as well as the special handling procedures associated with those documents.
Confidential status could be provided in several layers. Some documents may just have public sensitivities and need to be protected from public disclosure of the case documents. Others could have more sensitive status that restricts disclosure from the opposing party, although it may be disclosed to the opposing party's experts and legal team.
The special handling of confidential documents will involve special marking procedures as well as restrictions on disclosure. When electronic or native format files are concerned the marking may need to be suffixed or prefixed in the file name, since it may not be possible to alter the original document without altering the evidence itself.
As with privileged documents, confidential documents could have a clawback arrangement of sorts. In other words, documents that were inadvertently produced without the proper markings and restrictions could later be so designated and restricted. As with privileged documents some kind of disposition treatment of the inadvertently produced documents, like return or destruction of the inadvertently produced documents along with any copies subsequently made, will need to be included once they are detected.
Special Access Procedures
Sometimes it is just simpler to be open kimono and one party allow the other full access to its electronic data. It might be a gesture of openness or it might be a way to shift discovery costs to the requesting party. In either case, the parties will need to develop a plan for handling privilege and confidential data issues.
In some cases, the access is desired by requesting party that can be resisted by the producing party, particularly if it appears the requesting party's real agenda is just weaponization of the discovery process. In other cases, the producing party may be very content to let the requesting party have complete access. (see, Gaining Access to Computer Forensic Images)
In such cases, the parties generally agree that an expert will have full access to the digital data. The expert could be a neutral expert or it could even be the expert retained by one of the parties like the requesting party.
The expert will conduct whatever tests or searches are desired by the requesting party. In the event that the expert finds anything of interest, he first produces the data to the producing party for privilege review and other restrictive markings before producing the cleared data to the requesting party.
In such situations traceability and configuration issues are very important. Thus, the expert not only produces the data of interest but also other attributes about the data so that it can be traced back to its original source. The other attributes could include things like unique identifiers, original and produced file names, the path location, MD5 hash value, and file system date stamps.
For efficiency purposes, the process could also follow some of the analytic procedures discussed previously where the process starts with lists that are cleared by the producer before being supplied to the requester. The lists then become a basis for the requester to request certain documents for further review. The specifically requested documents are then provided to the producer for clearance before being provided to the requester. Essentially, these types of techniques provide a means to narrow the document productions and only produce those that have passed several layers of selection.
The procedures need not be limited to just documents. The produced results could be the results of forensic analysis as well.
Of course, under these special procedures, whatever they might be, the expert is only allowed to discuss those things with the requester that have been cleared for production. Consequently, it is important that both sides have confidence in the integrity of the expert.
8. Production of Documents
The production of documents is normally done in response to Rule 34 production requests. That prospect may still exist even when as part of step 6 discussed previously, data analytics, agreements were reached regarding the criteria for document production such as keyword hits and other data attributes.
Once the documents have been selected it is just a matter of processing and producing them. Of course, document review is usually done at this time as well, which makes this stage of the disclosure process the most costly portion.
Indeed, the processing and production portion of the plan is where a lot of different technical details will be resolved that if not specified could cause problems later on. The kinds of things that will be resolved in this section are the production format, usable form, metadata, duplicates, compound documents, special file types and the rate of production.
Format
The form of production is one of the topics to be addressed by the discovery plan under Rule 26(f)(3)(D). With respect to form there are several options. The most obvious is native format. The other option is to produce the documents in some kind of imaged format like TIFF or PDF. There are pros and cons to each of these.
While the image formats have been very popular for a lot of reasons, there is also added cost of production associated with the conversion process from native to the imaged format. From an efficiency perspective, native format is the most economical since it avoids the cost of conversion.
Of course, the native option only exists for ESI. Many cases can still include some amount of paper based documents. For paper based documents the options are to produce in paper or to produce in imaged format.
Making the choice between format is not simply an economic decision. There are other considerations as well that involve useful form.
Usable Form
The usable form issue can be quite significant when producing documents. One of the issues that has gained considerable interest in recent years is the application metadata, which is the internal data attributes about a document that are not visible when the document is displayed in its presentation format. Rather, this data is never displayed but is can be useful nonetheless.
While native forms contain the application metadata, the imaged formats will not reveal that data. Instead, when imaged formats are produced the metadata must be extracted. The problem there is that the available metadata is not the same between different document types. In fact, it could be very different between types and it is impractical to construct a process for capturing them all and a database for holding them all. Consequently, it has become common for parties to swap native documents even when they are swapping imaged based formats.
The application metadata is not the only usable form issue. When images have been produced without also providing the native format it has been decided that not producing searchable text along with the image format is not usable form. Of course, the parties could agree to produce only image formats if that was their choice and there are reasons for doing so.
When native documents are not produced and only an image format is produced then the only way to be searchable text is to create the searchable text by OCRing [Optical Character Recognition] of the image format. While OCR technology is much improved it is still subject to some error. The error could have adverse consequences of the usefulness of the searchable text. Consequently if the parties are going to agree to swap searchable text then they should also impose performance standards on the accuracy of the searchable text. Of course, achieving something highly accurate like 99 percent could be very expensive and difficult to achieve. Rather than imposing those costs on the producing party, what might be more reasonable is for the parties to swap images without searchable text and then each of them could decide how much they want to expend on getting the searchable text.
If they decide to forgo producing the searchable text and letting each party obtain its own, another factor that they will need to consider is the quality of the images. Low quality images will produce low quality searchable text. Consequently, to assure an image is in usable form the parties will also want to agree on specifications for the images such as resolution and sharpness. Of course, they could avoid the entire issue by just producing natively, at least for ESI. If the production includes any amount of paper based documents then the image based option is still possible as would be the option to simply exchange copies. In either case, the parties could include these details in their plan and avoid disputes later.
Metadata
It is often said that metadata is data about data. In the context of e-discovery metadata is not just the application metadata that is internal to a particular electronic document. In the context of e-discovery metadata is also the data that is captured in the document management database that pertains to the document.
When parties produce documents they expect to receive metadata about those documents from the producing party. Consequently, part of what the parties should decide upon is what metadata they will be exchanging along with the document.
Some of the obvious metadata elements are the custodian and/or identifier for the particular media when a custodian has more than one type of media. It is very common for a single custodian to have more than one piece of media once one considers things like attached devices. Similarly, when system resources like servers or backup tapes are considered it is also possible for the custodian to have several different media. Thus, issue to be resolved about metadata is not just the application metadata contained within the document itself.
Other common attributes besides file name and extension are the location of that particular file on a media. Still other attributes are file system date stamps. If the document is an e-mail message then it could be things like the subject, sender, recipient and message date.
While the above attributes are metadata that can be harvested from the media on which the document was located, there are other attributes that are determined during processing, like the MD5 hash used for subsequent verification and de-duplication, and bates numbering that is determined at the time of production.
While there may be many different metadata elements that could be desired by the parties and incorporated in their plan, there are many standard elements as well. Perhaps the bigger point is that if the parties have an expectation about what data should be swapped they should include it in their plan before expending considerable resources and then realizing the work was totally inadequate.
Besides what specific metadata attributes will be exchanged there is still another element on which the parties should agree. That additional element is the format and structure of the metadata and the produced documents.
It is not unusual that for the two sides to be using different document management systems. Ideally, each party will want to receive the documents and their respective metadata in a format and structure that can be ingested by their own system without any additional work. Although there are tools that are useful in making conversions, the most efficient will be when no conversions are needed.
Handling of Duplicates
Although duplicates have frequently existed in every production, at least since the birth of the copy machine, duplicates are particularly frequent in e-discovery. The use of e-mail further aggravates the problem as does various data retention practices and disaster recovery systems.
Parties may be able to help themselves by deciding how to handle duplicates. In its simplest form, the fact that duplicates are found in different periods of a backup rotation scheme is of no interest. As a result, the parties could decide to ignore the duplicates and only consider producing a unique version.
Things get more complex when the same document can be found on the machines of different custodians, although depending on the document type and nature of the case it may make no difference at all. If the document were a simply vendor invoice, it could make no difference how many copies existed and there they were found, particularly if there was no dispute about the invoiced item. On the other hand, if the document were the trade secret of a competitor, it could make a lot of difference about how many places it was found and the timing of its arrival at each location.
As part of their discovery plan the parties could decide how to handle duplicates. It need not even be a single rule for all documents. Rather, it could be quite stratified.
As a result of the preprocessing analytics the parties could know quite a lot about the population based on document types and the distribution across custodians. As a result of the scope definition and preservation effort they would also know a lot about the various storage systems being used by each custodian. With this information they could decide that certain document types should be produced as singles only across the entire document population, while other document types should be singles only within a particular custodian or storage media.
Even if the parties agree to produce singles only across the entire document population, which would produce the smallest document population and probably the greatest overall efficiency, they could rely on various document lists developed during preprocessing analysis to reveal all instances of a document's location when such information was of interest for a particular document.
Handling of Compound Documents
As discussed before, compound documents are those with many parts. In the normal sense of things, they tend to be compressed archives (zip files) and e-mails. The issue worthy of discussion by the parties is how to handle compound documents, particularly when not everything about a compound document is relevant to the case.
It is common practice that all parts of a compound document should be produced if any of it is responsive. With regards to e-mails this is likely the best practice to follow. With regard to compressed archives such a practice is questionable. A better approach may be production of just the responsive documents within a compressed archive while having a re-opener of sorts that permits subsequent production of other element should questions about their relevance develop.
Again, if the parties have followed the preprocessing analytic procedures discussed previously and shared the results, they likely will have lists that can inform them about the other documents that were captured in a compressed archive but not produced. Should a particular document prove significant the parties could first consider those lists to help them decide whether any additional files are needed.
Handling of Special File Types
When native files are being produced then all responsive documents will assuredly be produced. The question becomes when the production is format is an image format or includes an image format. In the case of image format based production there are several different native file formats that just sensible for images based production.
Spreadsheets are one file type that is not always suited for image based production. The issues with spreadsheets are many. First, the layout of the spreadsheet may not be symmetrical. Thus, when the data is reduced to a two dimensional matrix the result could include large amounts of blank pages.
Second, the spreadsheet could have many hidden columns and rows or even columns that are too narrow. Revealing the hidden columns and rows or resizing the rows could again disrupt its presentation and result in huge amounts of additional pages to be created and even make the presentation harder to comprehend.
The solution for spreadsheets is to either produce them all in native format or to limit the image based format to only a few pages while still producing the total file in native format. The exact procedure for handling spreadsheets is something that the parties could negotiate and specify in their plan.
Database tables are another problematic file type. Database tables are essentially tabular data like spreadsheets. Database tables could easily result in image based documents that are huge. In addition, the presentation of database contents in a tabular image based presentation could be very hard to comprehend. Another problem is that for database table data to be meaningful it often has to be related to the contents in other database tables. Without making the relationship the database table data could be totally incomprehensible. A final issue for databases is that in some forms the tables are not separately exposed but rather encapsulated in another kind of wrapper.
The solution for databases is very much like spreadsheets. It is best to rely mostly on native format production or to limit the image based production to a few pages while still producing the total database table file in native format.
The reality is that not all kinds of digital evidence is a document. There are other kinds of challenges as well with things like voice mails, audio and video. If the parties have used the preprocessing procedures they will have a good understanding about the kinds of data in the population. They can use this information to assess the data types and agree on what will be the best production formats and methods.
Rate of Production
It is very common that productions will be made in increments and not all at one time. The increments are particularly applicable when some kind of privilege review is being performed and a determination has to be made in a timely matter. In such cases, the parties will want to set time limits. The question is what those limits should be.
Frequently, limits in these cases are expressed in pages. The issue there is that pagination is an abstraction imposed by printer requirements. When producing native format documents pages have no significance. Even the gigabyte size could have little significance because current Microsoft Office documents utilize compression technology that can make conversion to document sizes hard to interpret.
It is hard to apply a magic parameter to solve the production rate issue. The parties will simply need to examine the document population and perhaps group the documents into similar type and then apply some kind of production rate.
9. Include Disputes Provision
Disagreements inevitably happen. Consequently, every good contract contains a disputes provision. The discovery plan should be no different.
The alternatives are not limited to a telecom with the judge or even a motion hearing. Indeed, the disputes provision does not have to strictly follow traditional disputes processes. In other words, it does not simply have to provide the adjudication of an issue. There are, in fact, several different approaches that could also be incorporated.
First, counsel could involve each side's technical experts and allow them to have open discussions about the issue. Counsel may have already discussed an issue with his technical expert but that is still not the same as free communications between two similarly skilled persons.
It is not even necessary that the two technical experts reach a conclusion or that their ideas be adopted without first subjecting them to more penetrating analysis off stage. Indeed, initial discussions where ideas are simply brainstormed and discussed could always be the precursor to a final negotiation and settlement.
Second, counsel could also include is a joint consultation with another expert--a neutral expert of sorts. Electronic discovery can be very technical. In addition, there could be several different ways to solve a problem. Thus, another thing that the disputes provision could include is consultation with a third party expert who can comment of the wisdom of opposing ideas, suggest an entirely different solution, or just share experiences about how certain processes are typically handled and let the parties pick their poison so to speak.
Clearly, there are all kinds of potential issues and all kinds of alternatives for settling them. Actual motion hearings would surely be the least desirable but may be unavoidable nonetheless. If the dispute actually escalated to that point then the dispute provision may also want to include a provision for the prevailing party to receive costs and fees.
10. Assign Cost Responsibility
The plan should also assign who will pay for the cost of the discovery process. Generally, each side will pay their costs.
Experts will likely be involved in assisting with the discovery in several areas such as helping to identify ESI sources, preprocessing analysis and final processing and production. Again, each side will typically pay for their own experts.
It is possible that the parties could also pick a common expert to assist with the discovery effort in hopes of gaining greater efficiency. In that case there may be cost allocations or other methods for determining cost responsibility. The allocation of costs could be simply based on the data being processed and who owns it. Then again their could be other agreements such as expanded access to one party's data in exchange for the costs of processing being shouldered by the requesting party. In the end, there are all kinds of deals that could be made as part of the negotiation of the discovery plan procedures.
When a multi-stage discovery approach is selected there could be other factors for determining cost allocation. For example, if the first stage, which would likely be the data sources with the greatest chance of having responsive and relevant ESI, produces no fruit then perhaps the cost of proceeding with the next stage should be totally born by the requesting party.
Similarly, there could be a disagreement between the parties about the scope of discovery. One party wants expansive discovery while the other sees it as just a fishing expedition. One way to resolve the scope issue is to include cost shifting provisions into subsequent stages of the discovery population. Perhaps costs would be shifted to the requesting party and then only shifted back to the producing party if relevant ESI was uncovered. The definition of relevant could even be structured to exclude duplicates of data already found unless the finding was more than just mere possession and amounted to material usage.
If neutrals are used for any aspect of the litigation or discovery process there are likely some special procedures that should be considered. Neutrals are in a tough spot and not just because of their duty for neutrality.
Someone is going to lose the case. If the neutral is in any way involved in that effort, even if it is strictly in the execution of their assigned duties, they will likely become a target for removal. For example, if the result of the neutral's preprocessing analytics it becomes clear that one side has spoliated evidence, the neutral is likely to become a target for removal by the disrobed party.
One way for the disrobed party to target the neutral is to manufacture a dispute with the neutral such as by not paying for the services provided. In such a situation the neutral is an a difficult position. If he does nothing the disrobed party will always claim that his work is always retribution for whatever services have gone unpaid. If the neutral tries to collect the unpaid amounts then again the disrobed party claims that his work is always retribution for whatever services have gone unpaid.
As a result, any compensation plan involving a neutral should be designed to protect the neutral's work from the shenanigans of disappointed parties. As such it may be best to have the neutral paid in advance or on a replenishing retainer basis for any work performed.
There could still be other considerations about the assignment of costs. For example, if spoliation is detected then the parties could have agreed in advance that the spoliating party pays the costs of the more detailed forensic analysis that is needed to evaluate the spoliation. (see, When Does Respondent Pay for Inaccessible Data)
Whatever cost allocation the parties negotiate they could also limit the costs to "reasonable" costs and describe what "reasonable" costs might be and include whenever the responsibility of one is shifted to the other. For example, if some kind of shifting is desired as a result of apparent spoliation then the analysis is not an open check book but one where the efforts employed are reasonable and proportional. Arguably such vague terms could lead to more motion practice so the parties may want to be more explicit and rule out inefficient methods like manual document review in favor of various technology assisted review techniques, for example. In other industries it is not uncommon for agreements to limit these kinds of costs either by their nature, amount or rate.
11. Disposition of the Data
The final element to be considered is the disposition of the data at the end of the case. This particular element does not really help with execution of the case. Rather, it just ensures that there is an ending and both sides can know when to cut any continuing costs that go with storing and safeguarding the data.
Both sides will need to retain their own data for the duration of the case. Since they will have exchanged data they each are also holding the other's data. So, the disposition issue not only involves their own data but the other's.
The parties can include what kind of notice is needed in order to trigger the destruction of the data. They can also include what procedures should be followed for the destruction such as wiping in addition to simple deletion. A final element can be certifications of data destruction that each side can exchange with the other.
Costs and Consequences of Developing a Good Plan
Developing a good plan takes both time and effort in addition to expertise. Frequently, project managers under estimate the importance of a good plan and move quickly to project construction for cost or schedule reasons. Such thinking is flawed, since it inevitably results in a longer project performance period and higher costs.
Over the years there have been many efforts to determine the optimum amount of advanced planning for any particular project. While each project is different and there is no magical ingredient, the rule of thumb has become that 15 to 20 percent of the overall budget should be allocated to advanced planning.
This 15 to 20 percent is not an additional cost, however. Rather, by spending that much on advanced planning the overall costs of the project is often cut by 50 percent or more when compared to similar projects without the planning effort.
Some have even thought to stratify projects needing advanced planning. The thinking was that only complex projects would benefit from the overhead of advanced planning. This has proven not to be the case, however. Studies have found that smaller projects took longer and cost more than more complicated projects when systems engineering disciplines were not fully applied to smaller projects.
Smaller projects will have less complicated issues. As a result of these less complicated issues, they will result in less planning costs. The idea that smaller projects should have less discipline in the planning effort simply undermines the benefits that planning will bring.
Conclusion
Successful managers of complex projects know the importance of good planning. In fact, successful managers of all kinds of complex endeavors like software products, hardware items, building construction, military operations and even professional services know the importance of good planning in delivering a final product that performs as intended as well as one that satisfies its cost and schedule criteria.
Litigation is a complex product, too. It has many parts like pleadings, orders, reports, hearings and the trial itself. One of the largest components to any litigation is discovery, which itself has many elements that must be optimized for efficiency and effectiveness.
The primary constraint for civil litigation is the, “just, speedy, and inexpensive determination of every action and proceeding” as expressed in Rule 1 of the FRCP. Unfortunately, that goal is seldom achieved because of poor planning and a failure to follow the rules in the first place.
The 26(f) conference and discovery plan are not just a requirement in a rule book. Indeed, they are the means by which clients and counsel bring sanity to the disclosure problem in order to accomplish Rule 1 objectives.
In traditional planning approaches the focus of the plan is on production. The planning and design phases are less rigorous and the flaws of the initial plan might only be recognized when production itself fails.
Systems engineering takes a more thoughtful approach to plan development. Perhaps most significant difference is that the thoughtfulness is moved forward in the development process in order to avoid wasteful production failures. In the process it improves problem decomposition and definition, requirements synthesis and then recomposition and process development. As a result, while developing the plan the actual objectives are sharpened as one evaluates decisions and the effects of trade-offs between the cost, schedule and performance/quality criteria.
Developing a good plan takes both time and effort in addition to expertise. Frequently, project managers under estimate the importance of a good plan and move quickly to project construction for cost or schedule reasons. Such thinking is flawed, since it inevitably results in a longer project performance period and higher costs. Thus, avoiding good planning as a cost savings measure never results in any cost savings. Rather, it results in just the opposite.
The rule of thumb has become that 15 to 20 percent of the overall budget should be allocated to advanced planning. The 15 to 20 percent is not an additional cost, however. Rather, by spending that much on advanced planning and employing proper system engineering disciplines the overall costs of the project is often cut by 50 percent or more when compared to similar projects without the planning effort.
Inquiries
To learn more about electronic discovery or
discuss a specific matter
770-777-2090
E-Mail